Пишем новый контроллер SDRAM ч.1
Предлагаю вам перевод цикла Writing a new SDRAM controller Part 1 автора Alastair M. Robinson.
В своем последнем посте я говорил о необходимости настроить контроллер SDRAM, используемый ядром Megadrive, чтобы заставить его работать на TC64V2 и, выпустив этот порт, пришло время обратить мое внимание на ядро PC Engine.
На самом деле этот вопрос уже несколько месяцев находился на заднем плане. Я начал портировать его в начале года, обнаружил, что он не работает на TC64V2, и еще не понимал - почему. Имея множество других проектов, чтобы занять себя, я некоторое время пренебрегал этим, но недавно вернулся к нему, вооружившись свежими знаниями о том, почему он не работает.
Настройка контроллера SDRAM на ядре Megadrive не была слишком сложной – мне пришлось пожертвовать небольшой потенциальной пропускной способностью, чтобы избежать шаблона чтения/записи/доступа к данным, который не работал на новом чипе Winbond, – но контроллер SDRAM ядра PCEngine имеет еще более строгие требования к времени и конечный автомат, который использует множество путей, чтобы время отклика было как можно ниже. Адаптировать его было бы гораздо труднее.
Вместо этого я переписал его в основном с нуля, так как хотел использовать другой подход.
Контроллер SDRAM, грубо говоря, должен выполнять три задачи. Он должен инициализировать чип, он должен выполнять арбитраж между различными подсистемами, которые хотят использовать оперативную память, и он должен выполнять фактическую передачу данных на чип и обратно.
Для ядра PC Engine он должен делать это на частоте 128 МГц, он не может заставлять порты VRAM ждать, иначе будут графические сбои – о, и он также должен втискивать несколько циклов обновления, иначе содержимое оперативной памяти будет повреждено.
Хорошее дело, мне же нравится бросать вызов, не так ли?
Итак, давайте рассмотрим типичную транзакцию чтения SDRAM.
Чипы SDRAM могут передавать данные пачками burst по 1, 2, 4 или 8 слов, а могут передавать всю страницу за раз. Можно одновременно записывать слово и читать в пакетном режиме, и можно прекратить выполнение пакета чтения или записи, если вам нужна только его часть. Мы также можем выбрать, поступают ли данные через 2 такта после того, как команда чтения регистрируется оперативной памятью, или через 3 такта. Режим CAS Latency 2 (CL2) обычно доступен только на скоростях до 100 МГц, но некоторые чипы (включая устройство Winbond в TC64) могут работать с CL2 до 133 МГц.
Ядро PC Engine не использует burst, мы передаем только одно слово за раз, что упростит этот анализ. (Ядро Megadrive использует пакеты чтения из двух слов, с которыми также довольно просто справиться.)
Итак, вот как выглядит одна транзакция чтения с точки зрения ПЛИС, а также с точки зрения микросхемы SDRAM, а также шины данных. Обратите внимание, что тактовый сигнал SDRAM немного опережают системный FPGA – этот фазовый сдвиг очень важен.
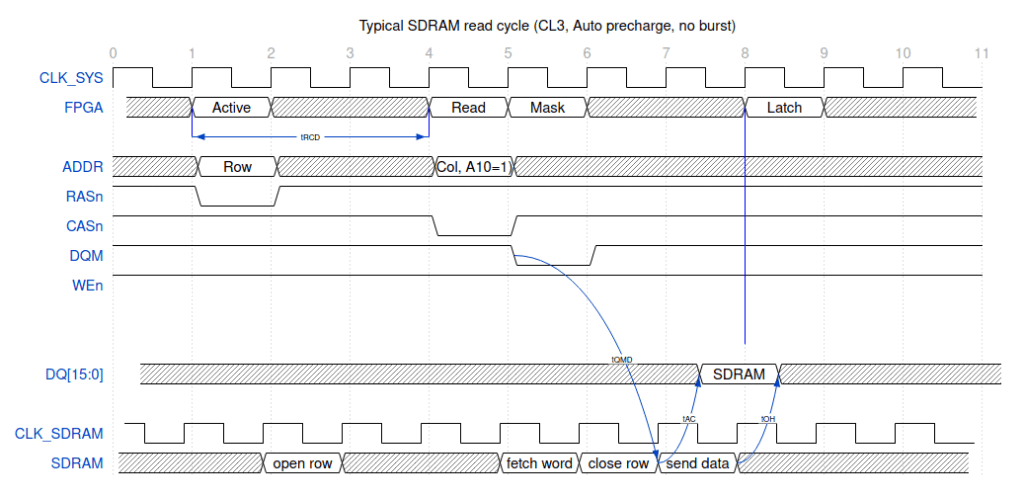 |
Итак, здесь происходит вот что, ПЛИС запускает команду “Bank Active” (RASn переходит в лог. "0"), чтобы открыть определенную строку данных. 32-мегабайтные SDRAM на целевых платах имеют 13 адресных выводов, что позволяет использовать 8192 строки на банк, поэтому мы используем полную адресную шину для выбора строки.
По истечении tRCD мы можем выдать команду вновь открытой строке, поэтому cбрасываем CASn и устанавливаем нужные биты адреса. Микросхема использует адресные биты 8:0 для адреса столбца (64-мегабайтные чипы также будут использовать A9), в то время как бит 10 имеет особое значение: автоматическая предварительная зарядка. Предварительная зарядка - это акт подготовки банка к открытию нового ряда. Если бит A10 установлен, когда мы выдаем команду чтения или записи, чип автоматически закроет строку при первой же возможности. Если A10 чист, то строка остается открытой, и мы можем выдать другую команду чтения или записи в ту же строку, а также мы можем выдать команду предварительной зарядки, если хотим закрыть строку вручную. В этом случае мы используем autoprecharge, поэтому строка закрывается сразу после выполнения чтения.
Особого внимания заслуживают сигналы DQM. Во – первых, их два - по одному на каждый байт слова, и их можно использовать для маскировки данных, как при чтении, так и при записи. Это позволяет писать только половину слова, не повреждая другую половину. Есть две проблемы: во-первых, маска вступает в силу сразу при записи, но при чтении она вступает в силу через два цикла. Это означает, что необходимо соблюдать особую осторожность при смешивании инструкций чтения и записи. Другая проблема заключается в том, что при чтении задержка DQMs всегда составляет 2 такта, хотя сами данные могут иметь задержку в 2 или 3 цикла. Если посмотреть на диаграмму, то если DQM не в лог "0" на 5-й такт, то чтение не будет запущено на 7-й такт и данные не поступят на 8-й такт.
Обратите также внимание, что существует задержка до того, как данные появятся на шине DQ. Данные становятся действительными при tAC (обычно около 5,5 нс) после первого тактового фронта и остаются действительными до tOH (обычно около 3 нс) после второго тактового фронта. Важно, чтобы мы фиксировали данные где-то во время этого окна действительных данных, и точная настройка синхронизации для организации этого является причиной сдвига фазы часов SDRAM по отношению к системным часам.
Еще одна вещь, которую следует отметить, заключается в том, что тот факт, что данные недействительны до tAC после тактового фронта, не означает, что шина данных остается в высоком импендансе до тех пор. На самом деле чип уже управляет шиной (хотя и с данными, которые еще не действительны) всего на tLZ (обычно между 0 и 1ns) после тактового фронта.
На приведенной выше диаграмме нам потребовалось девять циклов, чтобы прочитать слово – это не совсем впечатляющая производительность. К счастью, есть хитрости, которые мы можем использовать для повышения пропускной способности. Я упоминал в предыдущем посте, что микросхема SDRAM содержат четыре банка, которые ведут себя в значительной степени как четыре независимых чипа с общим интерфейсом. Ясно, что на приведенной выше диаграмме есть несколько циклов простоя, и мы можем использовать их для выдачи команд другим банкам.
 |
Здесь мы подаем команду каждому банку по очереди. Я не показал здесь все управляющие сигналы, но обратите внимание, как RASn и CASn чередуются довольно аккуратно. Поскольку Активная команда (RAS) не заботится о состоянии DQMs, вполне нормально маскировать транзакцию другого банка при выдаче активной команды (если только вы не используете модуль памяти MiSTer – это история для другого раза!).
На такте 10 мы могли бы выдать новую команду Act банку 0 и повторить цикл, чтобы последовательно передавать четыре слова каждые 10 циклов. Это значительное улучшение. Если бы мы использовали пакеты из 2 слов, то передавали бы 8 слов за 10 циклов.
В следующий раз я рассмотрю циклы записи и осторожность, необходимую при смешивании операций чтения и записи, и, возможно, расскажу о самом контроллере.
Адрес для контактов : imax9@narod.ru
Если вам понравились мои работы и вы желаете поддержать сайт - сделайте дотацию.
При копировании статьи – обязательна ссылка на авторство и источник. Без разрешения автора копирование запрещено.
© Максим Ильин 2021г.